DynamoDB
Differences Between Relational Data Design and NoSQL
Relational database systems (RDBMS) and NoSQL databases have different strengths and weaknesses:
In RDBMS, data can be queried flexibly, but queries are relatively expensive and don’t scale well in high-traffic situations (see First Steps for Modeling Relational Data in DynamoDB).
In a NoSQL database such as DynamoDB, data can be queried efficiently in a limited number of ways, outside of which queries can be expensive and slow.
These differences make database design different between the two systems:
In RDBMS, you design for flexibility without worrying about implementation details or performance. Query optimization generally doesn’t affect schema design, but normalization is important.
In DynamoDB, you design your schema specifically to make the most common and important queries as fast and as inexpensive as possible. Your data structures are tailored to the specific requirements of your business use cases.
Approaching NoSQL Design
The first step in designing your DynamoDB application is to identify the specific query patterns that the system must satisfy.
In particular, it is important to understand three fundamental properties of your application’s access patterns before you begin:
Data size: Knowing how much data will be stored and requested at one time will help determine the most effective way to partition the data.
Data shape: Instead of reshaping data when a query is processed (as an RDBMS system does), a NoSQL database organizes data so that its shape in the database corresponds with what will be queried. This is a key factor in increasing speed and scalability.
Data velocity: DynamoDB scales by increasing the number of physical partitions that are available to process queries, and by efficiently distributing data across those partitions. Knowing in advance what the peak query loads might help determine how to partition data to best use I/O capacity.
After you identify specific query requirements, you can organize data according to general principles that govern performance:
Keep related data together. Research on routing-table optimization 20 years ago found that “locality of reference” was the single most important factor in speeding up response time: keeping related data together in one place. This is equally true in NoSQL systems today, where keeping related data in close proximity has a major impact on cost and performance. Instead of distributing related data items across multiple tables, you should keep related items in your NoSQL system as close together as possible.
As a general rule, you should maintain as few tables as possible in a DynamoDB application.
Exceptions are cases where high-volume time series data are involved, or datasets that have very different access patterns. A single table with inverted indexes can usually enable simple queries to create and retrieve the complex hierarchical data structures required by your application.
Use sort order. Related items can be grouped together and queried efficiently if their key design causes them to sort together. This is an important NoSQL design strategy.
Distribute queries. It is also important that a high volume of queries not be focused on one part of the database, where they can exceed I/O capacity. Instead, you should design data keys to distribute traffic evenly across partitions as much as possible, avoiding “hot spots.”
Use global secondary indexes. By creating specific global secondary indexes, you can enable different queries than your main table can support, and that are still fast and relatively inexpensive.
These general principles translate into some common design patterns that you can use to model data efficiently in DynamoDB.
GSIs in DynamoDB
Global Secondary Indices (GSIs) can be used to resolve queries in DynamoDB. To speed up queries on non-key attributes, you can create a global secondary index. A global secondary index contains a selection of attributes from the base table, but they are organized by a primary key that is different from that of the table. The index key does not need to have any of the key attributes from the table. It doesn’t even need to have the same key schema as a table. Because of this, in the GSI, records can be non-unique.
In this case, we can use the vendor code as the partition key, and the sort key as the weekend day.
Problem is the sort key is a date range, drawback of dynamoDB is that it cannot do some sort of range search.
You can’t do query of that kind. DynamoDB is sharded across many nodes by hash key, so doing a query without hash key (on all hash keys) is essentially a full scan. A hack for your case would be to have a hash key with only one value for the whole table, but this is fundamentally wrong because you loose all the pros of using DynamoDB. See hot hash key issue for more info: http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/GuidelinesForTables.html
Maybe we can do some sort of binary search? But in this data, weekend day is for 1 week, month data, might have to do 4 keys In this case, dynamodb might not be the best
Query in DynamoDB
Class called dynamodb query expression, you can define which attribute you want to use for the query You can define a condition for the expression, define larger than, equals, even other conditions, or some other math condition
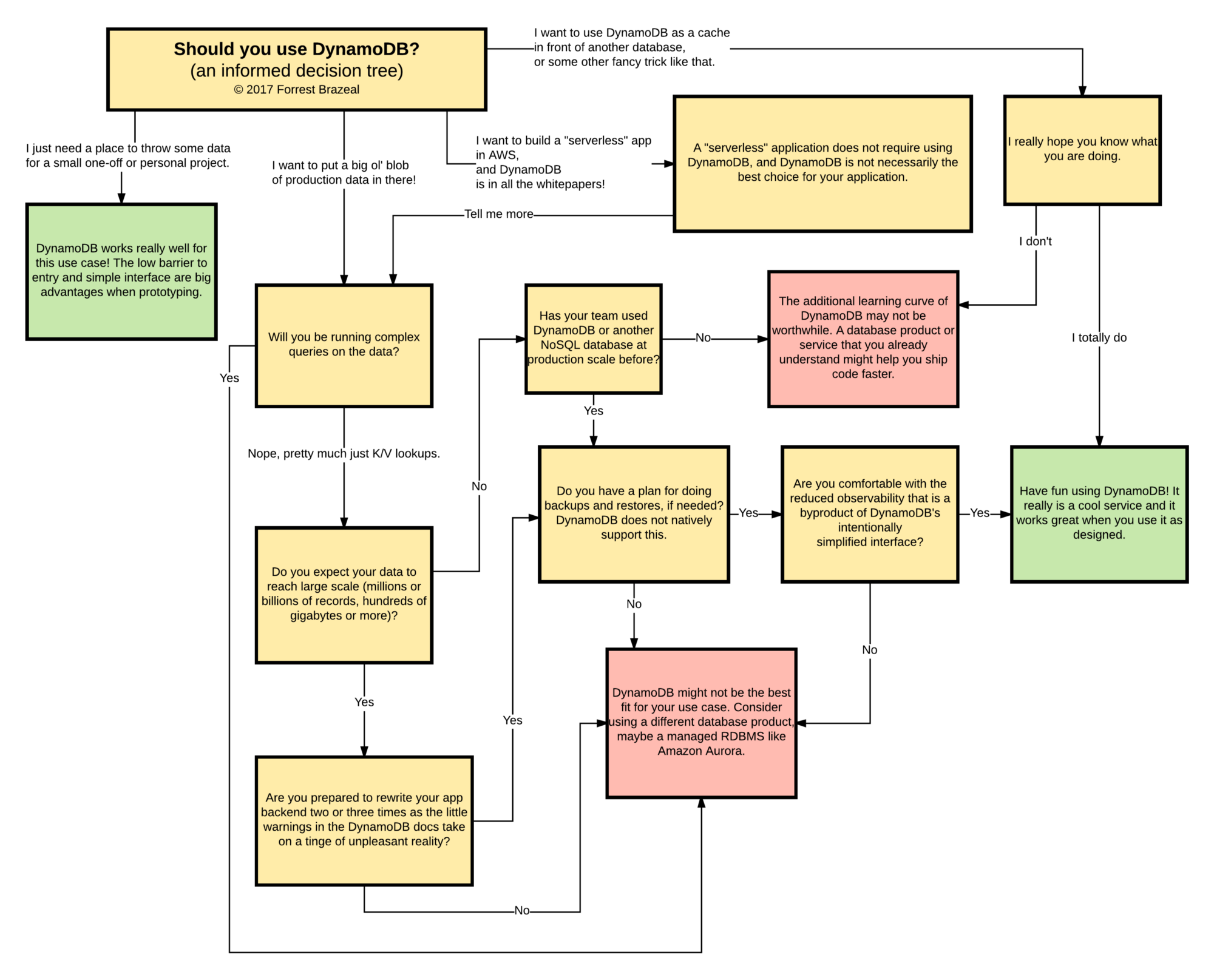
When not to use DynamoDB
When not to use DynamoDB:
When multi-item or cross table transactions are required When complex queries and joins are required When real-time analytics on historic data is required
Should I use DynamoDB?
 DynamoDB
DynamoDB
uid: DynamoDB tags: #amazon