Manan Khattar
Internship Retrospective
Friday, May 29, 2020
Some Stuff I Worked On
- Built in Markdown functionality in Datanav #3734
- Put the final nail in Airflow’s coffin #4048
- Created a
KafkaMockmodule for convenient testing. #4205 - Ported the Decline ingester to the loader framework #4505
- Created a Hypothesis testing framework to test Redshift loader processing scripts #4769
Datanav Demo
Turning Off Airflow
- Converted existing
airflow_dagsin BUILD files toargo_dags - Some were easier than others - most complicated ones were the FTP and Decline ingesters
- Made final nuking PR - removed 99% of all instances of Airflow from the codebase
- Worked with Josh K. to delete Airflow Kubernetes deployment/namespace, delete the Airflow database from Postgres, etc
Turning Off Airflow
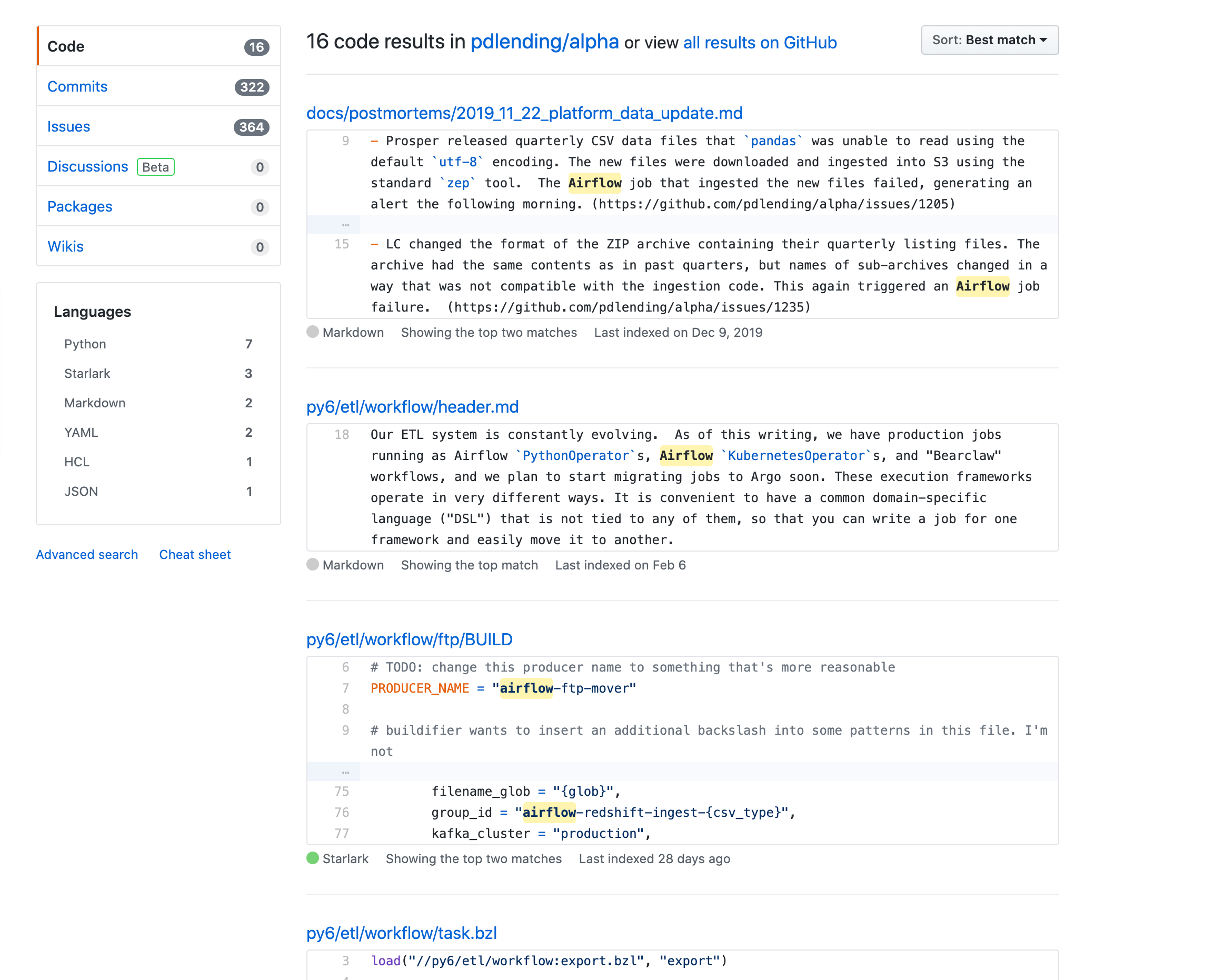
Only 16 instances of Airflow in the codebase! (Mostly old documentation/historical artifacts).
 right
right
Kafka Mock
Setup
- Writing tests for ETLs is hard, especially if they interact heavily with Kafka
- Confluent Kafka is annoying to use
- Josh K. made a wrapper for the Kafka functionality we actually use (
py6/util/kafka.py) KafkaMockshould have the same functionality as theKafkamodule (but work in local memory)
[.build-lists: false]
Kafka Mock
YAKs
- Wrote a script to download sample (non-test-id) messages from a given topic (
py6/kafka/inspection.py)
def download_messages(topic_name,
group_id="message_downloader",
cluster_name="staging",
num_messages=20,
filter_func=None):
# type: (str, str, str, int, Optional[Callable[[kafka.Message], bool]]) -> None
"""
This script can be used when one wants to download sample messages from a specific Kafka topic,
for use in testing and scripts that test ETLs.
The filter function cannot be passed in through the command-line, so the command-line interface
to this function has no filtering capability by default. When called programmatically, however,
the filter function can be used to filter out the Kafka messages that shouldn't be downloaded
from the topic.
"""[.build-lists: false]
Kafka Mock
Intermediary steps
- Incrementally passed the unit and integration tests of the
Kafkamodule
alpha/py6/testing on manan/hypothesis-testing-for-loader [$?] via thm3 via 🐍 system
➜ pytest /Users/manankhattar/alpha/py6/kafka/test_kafka_mock.py
=================================================================================================================================== test session starts ====================================================================================================================================
platform darwin -- Python 3.7.6, pytest-3.5.0, py-1.8.1, pluggy-0.6.0
hypothesis profile 'default' -> database=DirectoryBasedExampleDatabase('/Users/manankhattar/alpha/py6/testing/.hypothesis/examples')
rootdir: /Users/manankhattar/alpha, inifile: pytest.ini
plugins: hypothesis-4.32.3, Flask-Dance-2.2.0, flaky-3.4.0
collected 22 items
../kafka/test_kafka_mock.py ...................... [100%]
===Flaky Test Report===
===End Flaky Test Report===
================================================================================================================================ 22 passed in 0.11 seconds =================================================================================================================================Kafka Mock
[.build-lists: false]
- Mostly works out of the box! (A bit of setup/monkeypatching required)
[.column]
@pytest.fixture(scope="module")
def setup(cluster_name):
# type: (str) -> None
# creates a mock cluster and a mock topic
curr_cluster = kafka_mock.new_cluster(cluster_name)
curr_topic = kafka_topics.ProsperDeclineCallsTopic
json_file_path = os.path.join(
os.path.dirname(__file__),
"sample_messages_decline_program.prosper.ProsperDeclineAPICall.api_calls.json")
# add topic to cluster
curr_cluster.ensure_topic(curr_topic)
# adds messages from json to the new topic
kafka_message_list = json_to_list_of_messages(json_file_path, curr_topic)
# makes a new mock producer
curr_producer = kafka_mock.Producer( # type: ignore[type-var]
topic=curr_topic,
cluster="staging",
)
# mock producer sends messages from json to mock cluster
for message in kafka_message_list:
curr_producer.reliable_send(message.value(), message.timestamp())[.column]
@pytest.fixture(scope="function")
def mocking_and_monkeypatching(monkeypatch):
# type: (_pytest.monkeypatch) -> None
# do monkeypatching
monkeypatch.setattr(kafka, "Consumer", kafka_mock.Consumer)
monkeypatch.setattr(kafka, "Authenticator", MagicMock())Decline Ingester / Loader framework
Setup
- Previously, the decline ingester had its own processing script (
py6/etl/scripts/ingest_decline_calls.csv) - Written before we decided on a common framework for all scripts that load messages from Kafka and put them in Redshift (
kafka_to_redshift.Loader) - Take logic from
ingest_decline_callsand put it into a single processing function:(kafka_to_redshift.ProcessorDataType) -> pd.DataFrame
Decline Ingester / Loader framework
YAKs
- Usage of
argparsein thekafka_to_redshift.Loadermade it difficult to write tests (couldn’t directly pass in command line arguments) - Some discrepancies in the arguments that could be passed into the loader programmatically vs from the command line
Decline Ingester / Loader framework
YAKs (Small changes to kafka_to_redshift.Loader)
- Extracted all argument parsing functionality from the
runmethod inkafka_to_redshift.Loader - Create a class method,
kafka_to_redshift.Loader.parse_args, that can parse command line arguments and then pass them to the initializer - Make all arguments in the
__init__method of the Loader required. (Used for testing)
Decline Ingester / Loader framework
/ End YAK digression
[.column]
- Made 4 new loaders - 2 each for LC and Prosper, prod and staging
- Currently turned off
[.column]
import pandas as pd
from py6.etl.redshift.tools import table_helpers
from py6.etl.redshift.tools import kafka_to_redshift
from py6.etl.redshift.processors import ingester_processing
TABLE_NAME = table_helpers.infer_table_name(__file__)
PLATFORM_PROCESSOR = ingester_processing.ProsperDeclineIngestionProcessor()
def process(messages):
# type: (kafka_to_redshift.ProcessorDataType) -> pd.DataFrame
batch_processor = ingester_processing.DeclineBatchProcessor(PLATFORM_PROCESSOR, TABLE_NAME)
return batch_processor.process(messages)
if __name__ == "__main__":
kafka_to_redshift.Loader.parse_args(
topic=PLATFORM_PROCESSOR.kafka_topic,
table=TABLE_NAME,
processor=process,
cluster="production",
db="prod").run()Kafka Hypothesis Generator
Intro to Hypothesis
[.column]
- Think of a normal unit test as being something like the following:
- Set up some data.
- Perform some operations on the data.
- Assert something about the result.
- Hypothesis lets you write tests which instead look like this:
- For all data matching some specification.
- Perform some operations on the data.
- Assert something about the result.
- (From hypothesis docs)
[.column]
def encode(input_string):
count = 1
prev = ""
lst = []
for character in input_string:
if character != prev:
if prev:
entry = (prev, count)
lst.append(entry)
count = 1
prev = character
else:
count += 1
entry = (character, count)
lst.append(entry)
return lst
def decode(lst):
q = ""
for character, count in lst:
q += character * count
return qKafka Hypothesis Generator
Intro to Hypothesis
[.column]
from hypothesis import given
from hypothesis.strategies import text
@given(text())
def test_decode_inverts_encode(s):
assert decode(encode(s)) == s[.column]
Falsifying example: test_decode_inverts_encode(s='')
UnboundLocalError: local variable 'character' referenced before assignmentKafka Hypothesis Generator
Setup
- To test if the decline ingester port worked properly, wanted to use Hypothesis to fuzzy test the ingester script with well-formatted Protobuf messages
- Create a general strategy that can generate messages for Hypothesis testing from a given Kafka topic
Kafka Hypothesis Generator
Demo
Kafka Hypothesis Generator
Sample usage
from py6.etl.redshift.loaders.prosper import my_etl_module
from py6.testing import kafka_to_redshift_helpers
sample_message_path = "path/to/sample/message.json"
Your sample message JSON should be formatted like this:
# [
# {
# "timestamp": 0.001,
# "value": google.protobuf.json_format(kafka_message_1)
# },
# {
# "timestamp": 0.002,
# "value": google.protobuf.json_format(kafka_message_2)
# },
# ...
# ]
#
@kafka_to_redshift_helpers.unit_test_loader(my_etl_module.TOPIC, sample_message_path)
def test_my_loader(processor_input):
df = my_etl_module.processor(processor_input)
# User needs to write assertions about the final dataframe
assert len(df[df['interest_rate'] > 0]) == 0 # bogus example assertionKafka Hypothesis Generator
Next steps
- Doesn’t currently work on Prosper topic - need to make an effective generator for TU attributes
- Can use hypothesis testing for testing functions involving Pandas dataframes as well
- @ezzeri Some processors in
dim_loanare good candidates
- @ezzeri Some processors in
That’s it!
Thank you all!
uid: 202005291000 tags: #theorem #presentation